制作起因 关注了几个很活跃的中文开发者,比如@karminiski-牙医,@Easy,他们都是有多年开发经验的技术大佬。他们的Github中有很多星标过的内容,可以看成是“大佬的肯定”的项目,具有一定的探索、参考、使用的价值。然而我发现Github的星标仓库搜索功能比较鸡肋,经常搜索不出来我想要的东西。因此打算结合向量搜索构建一个星标仓库搜索的工具,起名就叫“观星者(StarGazer)”。这次的制作思路还是我的常用技术,Flask作为后端,前端还是手写HTML/CSS/JS+jQuery,部署依然是白嫖Vercel,数据库也尝试一下和Vercel合作(?)的数据库UpStash。
这个项目的现阶段还是一个初期跑通的阶段,希望能在新年学一些新的技术,比如Vue3+tailwindcss重写前端,FastAPI或者使用Rust作为后端完善这个项目 。
需求分析 这个项目主要要进行两部分的内容:
爬取指定用户的星标仓库并将其放入向量数据库,同时还要有一个更新数据库的功能;
根据用户的输入放入对向量数据库进行查询,并将返回的结果根据设定的相似度阈值进行筛选,渲染返回结果
第一部分的内容主要是爬虫,第二部分的内容主要是交互,应该都不难,但要做好还是要花点心思。
基本设计 我想做成一个像素风格的。主色调用暗色+青色,再模仿一下perplexity的布局。整体布局是这样:
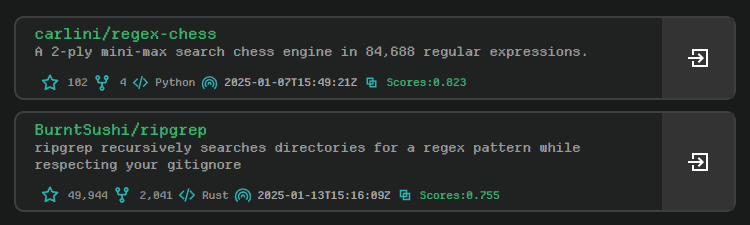
搜索结果的卡片:
左边的debug窗口是我自己喜欢的一种风格,所以不喜欢的也可以删掉^_^
开始Coding! 开发环境设置 Windows下开发,Git bash作为终端,所有和密钥相关或者相关部署设置都用环境变量,然后用os.environ["XXXXXX"]获取对应值。
编程辅助选择Cline+DeepSeekV2.5-Coder,不赋予修改代码权限。我还是更喜欢自己手动review AI的代码,不能完全解放双手。
爬取数据 一开始我想的是应该有什么API获取星标仓库数据的吧,但是真的没找到…Github这个文档本身就没有搜索功能!气死我了。然后我就开始硬爬吧,发现需要的headers就两部分内容:
1 2 3 4 { "user-agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 Edg/132.0.0.0" , "content-type" : "text/html; charset=utf-8" }
然后定位到这个URLhttps://github.com/{GITHUB_USERNAME}?tab=stars,用requests+BeautifulSoup解析一下就可以获取很多信息,比如使用的语言,星标数量,Forks数量,最近更新日期,项目链接,仓库作者信息,仓库介绍等,所以写个函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def process_single_page (url ):"user-agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 Edg/132.0.0.0" ,"content-type" : "text/html; charset=utf-8" "lxml" )'div' , class_ = "col-lg-12" )"div" , class_='f6 color-fg-muted mt-2' )"span" ,attrs={"itemprop" : "programmingLanguage" }) for each in langsdiv]if each else "None" for each in langs]"a" ,class_="Link--muted mr-3" ) for each in langsdiv]0 ].text.strip().replace("\n" ,"" ) for each in snfs]0 if len (each)==1 else each[1 ].text.strip().replace("\n" ,"" ) for each in snfs]"p" ) for each in search_field.findAll("div" , class_='py-1' )]"\n" ,"" ) if each else "Woops! there is No description about this project" for each in temp]"https://github.com" "a" )['href' ] for each in search_field.findAll("h3" )]"/" )[-1 ] for each in links]"datetime" ) for each in search_field.findAll("relative-time" )]return [{"RepoName" :name, "Description" :des, "Link" : link, "Language" :lang, "Star" :star, "Fork" :fork, "UpdateTime" : update}for name, des, link, lang, star, fork, update in zip (names, descriptions, links, langs, stars, forks, update_time)]
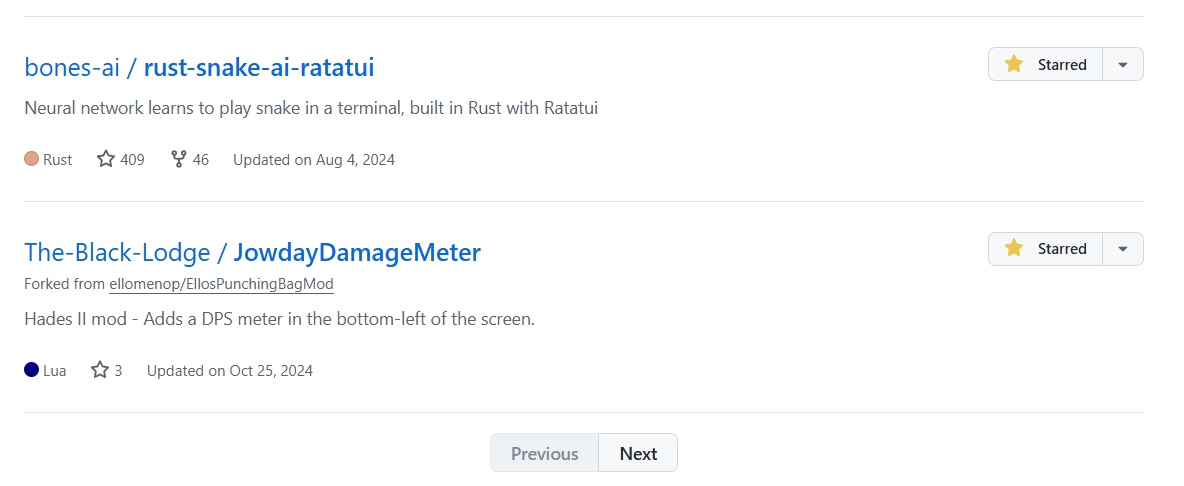
但是这只能处理单页30个仓库的数据,后面几页还需要定位到下方的Next按钮获取下一页的数据:
所以还要写一个递归获取所有页数据的函数。我偷懒了,直接用Cline+DeepSeekV2.5写的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 def find_next (base_url: str , max_depth: int = 100 , current_depth: int = 0 , url_list: Optional [List [str ]] = None ) -> List [str ]:""" 递归爬取所有URL :param base_url: 当前要爬取的URL :param max_depth: 最大递归深度,防止无限递归 :param current_depth: 当前递归深度 :param url_list: 存储所有URL的列表 :return: 包含所有URL的列表 """ if url_list is None :if current_depth >= max_depth:print (f"达到最大递归深度 {max_depth} " )return url_listtry :'lxml' )"div" , class_="BtnGroup" )if not search_field:return url_list"a" , attrs={"rel" : "nofollow" })for each in urls:if each.text == "Next" :"href" )return find_next(base_url=next_url, 1 ,return url_listexcept requests.RequestException as e:print (f"请求失败: {e} " )return url_list
到目前为止,都很顺利!
交互设计 主要要对两个事件做处理:一个是数据的同步,一个是输入反馈。这里面我就做了一些简单的动画,例如使用了转圈的黄色来表示正在处理、红色表示出现异常,以及绿色表示操作成功:
结果的反馈则是渐进式的,以相对平滑的动画呈现搜索的结果。
这里的文字显示还是有点小问题,不过后面会改的(
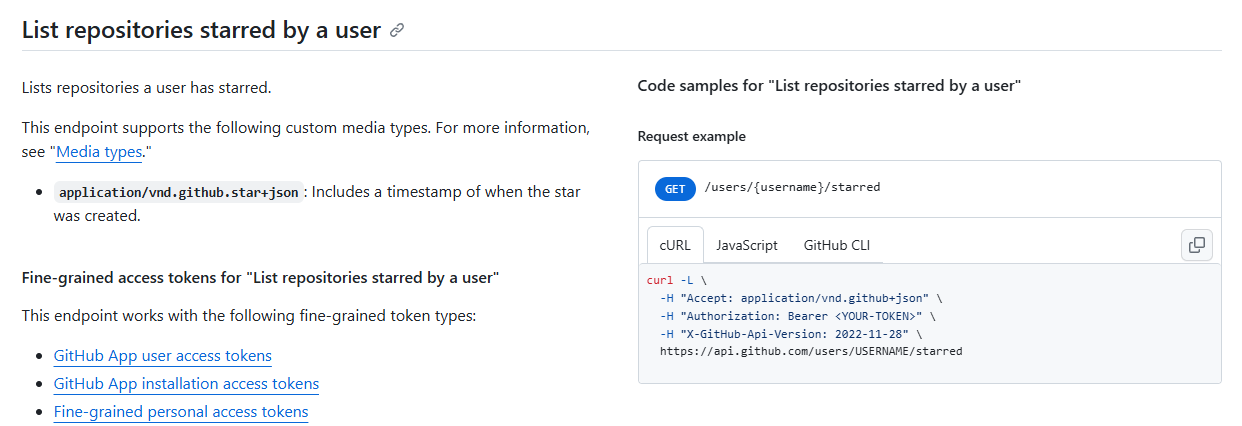
优化 同步数据+数据入库 爬取数据那里我真感觉不对劲,Github这么大的使用量,难道真的没有对应的REST API吗?我于是狠狠地一个个点进去文档仔细找,还真给我找到了 ,🔗在这里 :
这个支持分页,每页最多可以拉100条数据,在Github个人设置那里开启一个token就可以使用API了。接下来我们可以用异步来优化!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 import aiohttpimport asyncioimport osimport requestsfrom bs4 import BeautifulSoupimport lxml'GITHUB_TOKEN' ]'karminski' "http://127.0.0.1:7890" def get_params (GITHUB_USER ):f"https://github.com/{GITHUB_USER} ?tab=stars" "user-agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 Edg/132.0.0.0" ,"content-type" : "text/html; charset=utf-8" }, "https" : "127.0.0.1:7890" , "http" : "127.0.0.1:7890" }'lxml' )"a" , attrs={"aria-current" :"page" }).find("span" ,class_="Counter" ).get("title" ).replace("," ,"" )"a" , attrs={"itemprop" : "image" }).get("href" ).replace("https://avatars.githubusercontent.com/u/" ,'' )[:-4 ]return user_id, int (stars_num)//100 +1 async def fetch_with_ (url, headers, proxy ):async with aiohttp.ClientSession() as session:async with session.get(url, headers=headers, proxy=proxy) as response:return await response.json()async def fetch_multiple_urls (github_user, headers, proxy ):f"https://api.github.com/user/{user_id} /starred?per_page=100&page={i} " for i in range (1 , stars_num+1 )for url in urls]return await asyncio.gather(*tasks)"Accept" : "application/vnd.github+json" ,"Authorization" : f"{GITHUB_TOKEN} " ,"X-GitHub-Api-Version" : "2022-11-28" ,async def main ():await fetch_multiple_urls(GITHUB_USER, headers, proxy)for item in results for subitem in item]return resultsif __name__ == "__main__" :import timeprint (len (results))print (f"Time cost:{time.time() - st} seconds" )
在benchmark.py中有一个同步和异步对比的结果,感兴趣的可以自己根据情况注释掉proxy后运行:
1 2 3 4 5 6 7 $ python benchmark.py
考虑一下Vercel里面的默认超时是10s,这个的含金量希望你也能懂~
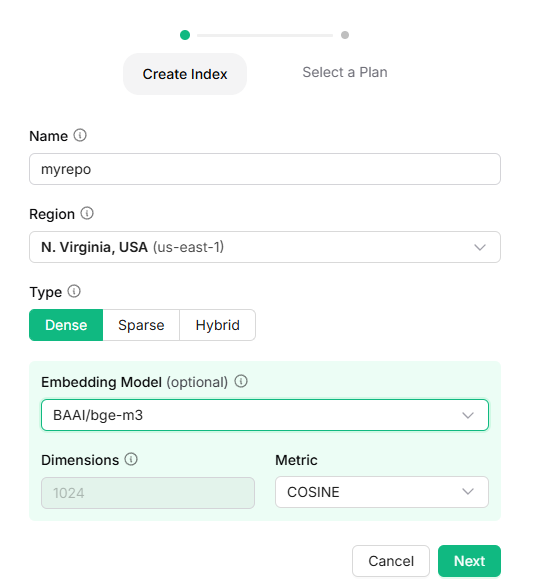
数据库 我使用的是Vector - Upstash 的向量数据库。按照使用指引可以非常非常方便地进行配置。你可以参考我的向量数据库配置:
我使用了BAAI的bge-m3模型作为Embedding的工具。Upstash的Python-SDK 提供了很简单的增删改查的样例:
向量数据入库 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from upstash_vector import Index, Vector"https://YOUR-vector.upstash.io" , token="YOUR_TOKEN" )id ="id1" ,"Enter data as string" ,"metadata_field" : "metadata_value" },"Enter data as string" ,1 ,True ,True ,
只需要稍加修改就可以使用database.upsert()方法把爬取到的Github星标数据入库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @app.route("/asyncupdate" async def asyncupdate ():try :for cindex, each in enumerate (chunk_list):f"id{cindex*1000 + index+1 } " ,f"{value['full_name' ]} : {value['description' ]} " ,value) for index,value in enumerate (each)print (f"[Upstash] Upload data to vecdb: {vecdb_res} ." )return {"res" :vecdb_res,"len" :len (results)}except Exception as e:print (e)return {"res" : "[Vecdb] Error Indexing data." }
删除脏数据 当然,如果不小心放了一些脏数据进去,也可以这样根据入库时候的id范围进行删除:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from upstash_vector import Index,Vectorimport os'GITHUB_USER' ]'GITHUB_TOKEN' ]'DATABASE_TOKEN' ]"DATABASE_URL" ]f"https://github.com/{GITHUB_USER} ?tab=stars" f"id{i} " for i in range (1 ,120 )]print (res.deleted)
完工! 完成的成果放在了vercel 上面啦!如果大家喜欢或者感兴趣的话,可以fork回去改一改来玩~